# Intro to Distributed Tracing With Tempo, OpenTelemetry, and Grafana Cloud
URL:: https://grafana.com/blog/2021/09/23/intro-to-distributed-tracing-with-tempo-opentelemetry-and-grafana-cloud
Author:: Simon Aronsson
## Highlights
> What is observability? Observability is the practice of taking an opaque system, or action in a system, and making it available for us to inspect and reason about through its outputs. ([View Highlight](https://read.readwise.io/read/01fgvkej597z615ycq7wtj950v))
> The once-straightforward way of debugging is now no longer an option. There is no longer any obvious correlation between the calls of each service, and trying to piece them together using, for instance, timestamps or other metadata will soon grow unmanageable. In a system with as few as 10 requests per second, the manual labor would be overwhelming, and we’d likely get it wrong more often than not. ([View Highlight](https://read.readwise.io/read/01fgvkg6h72vh1xfg6dq1wmenk))
- Note: Microservice disadvantaged in observability
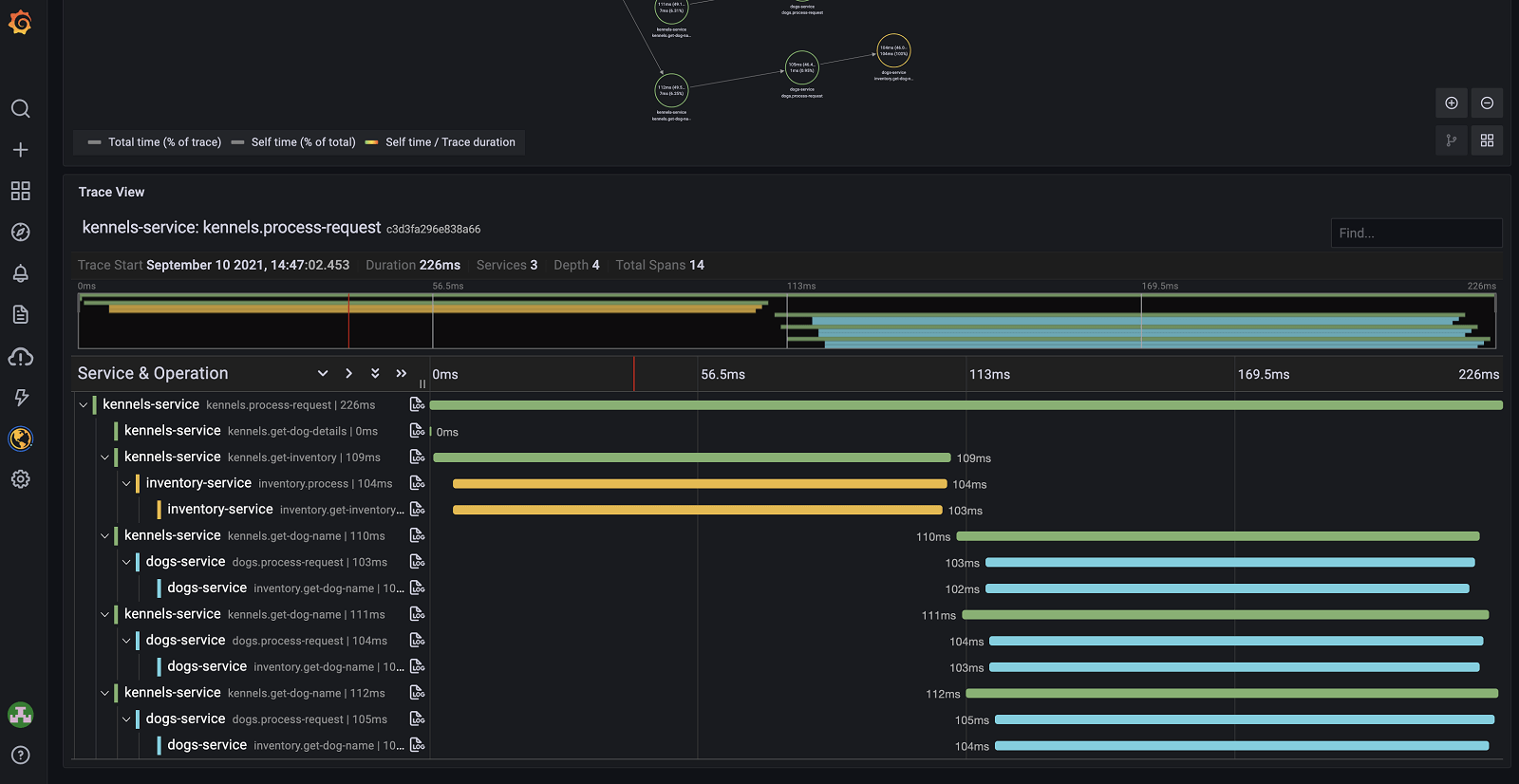
> Tracing, or in this case distributed tracing, is an attempt to solve the loss of coherence in distributed systems. ([View Highlight](https://read.readwise.io/read/01fgvkhpf65rz75w8gcbgyyyrv))
> Should we always default to adding distributed tracing to our applications? Not necessarily. If we’re already able to reason about the internals of our system in a satisfying way, there might be other activities available that would bring more value to the team or the product.
> However, if we currently feel that we lack the means to do any of the following, then distributed tracing might be just what we need to:
> • Easily see the health of the services part of this system.
> • Find the root cause for errors and defects that surface in production.
> • Find performance issues and pinpoint where and why they occur. ([View Highlight](https://read.readwise.io/read/01fgvkj1by4j32t2ammhkp9gqn))
---
Title: Intro to Distributed Tracing With Tempo, OpenTelemetry, and Grafana Cloud
Author: Simon Aronsson
Tags: readwise, articles
date: 2024-01-30
---
# Intro to Distributed Tracing With Tempo, OpenTelemetry, and Grafana Cloud

URL:: https://grafana.com/blog/2021/09/23/intro-to-distributed-tracing-with-tempo-opentelemetry-and-grafana-cloud
Author:: Simon Aronsson
## AI-Generated Summary
Learn how tracing, one of the pillars of observability, helps us deduce what’s happening in an application — and get a step-by-step demo of how to set it up.
## Highlights
> What is observability? Observability is the practice of taking an opaque system, or action in a system, and making it available for us to inspect and reason about through its outputs. ([View Highlight](https://read.readwise.io/read/01fgvkej597z615ycq7wtj950v))
> The once-straightforward way of debugging is now no longer an option. There is no longer any obvious correlation between the calls of each service, and trying to piece them together using, for instance, timestamps or other metadata will soon grow unmanageable. In a system with as few as 10 requests per second, the manual labor would be overwhelming, and we’d likely get it wrong more often than not. ([View Highlight](https://read.readwise.io/read/01fgvkg6h72vh1xfg6dq1wmenk))
Note: Microservice disadvantaged in observability
> Tracing, or in this case distributed tracing, is an attempt to solve the loss of coherence in distributed systems. ([View Highlight](https://read.readwise.io/read/01fgvkhpf65rz75w8gcbgyyyrv))
> Should we always default to adding distributed tracing to our applications? Not necessarily. If we’re already able to reason about the internals of our system in a satisfying way, there might be other activities available that would bring more value to the team or the product.
> However, if we currently feel that we lack the means to do any of the following, then distributed tracing might be just what we need to:
> • Easily see the health of the services part of this system.
> • Find the root cause for errors and defects that surface in production.
> • Find performance issues and pinpoint where and why they occur. ([View Highlight](https://read.readwise.io/read/01fgvkj1by4j32t2ammhkp9gqn))