# Observability vs. Monitoring Debate: An Irreverent View
URL:: https://ubuntu.com/blog/observability-vs-monitoring-debate-an-irreverent-view
Author:: Michele Mancioppi
## Highlights
> Trope 1: Pillars ([View Highlight](https://read.readwise.io/read/01fsm2f6gh3gznnb86kjfxaa48))
> The word “pillar” is often used in the observability/monitoring context to represent which types of telemetry are collected and processed by a tool, e.g., metrics, logs, distributed tracing, synthetic monitoring, production profiling, and so on. Some telemetry types are very well understood and widely adopted, such as logs and metrics; others less so, such as distributed tracing, synthetic monitoring and continuous profiling. (Profiling in and of itself is well understood from a development and QA standpoint, but not how to use profilers continuously in production.) ([View Highlight](https://read.readwise.io/read/01fsm2eg15kdh2nd3fhgetfnx8))
> In reality, there are many types of telemetry, and which ones are needed depends on the particular use case. What there surely isn’t, is a “golden set” of telemetry types that give you just what you need no matter what. The kind of telemetry you need is very dependent on what your application does, who uses it, and how. ([View Highlight](https://read.readwise.io/read/01fsm2f2gjjywqz8mbgr59nsew))
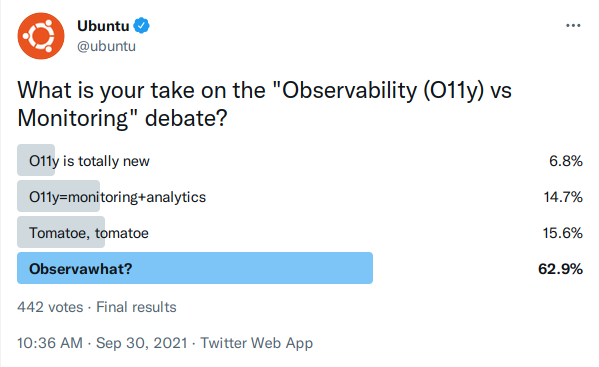
> Trope 2: Observability is monitoring plus powerful analytics ([View Highlight](https://read.readwise.io/read/01fsm2f8pat5yymvvfxd96mzx5))
> It is true that, in the past few years, the flexibility of analyzing telemetry has improved by leaps and bounds. How those *incremental improvements* make a sharp cut between monitoring and observability is honestly beyond me. ([View Highlight](https://read.readwise.io/read/01fsm2gkhg6hmww90zr6x8c97w))
> Trope 3: Artificial intelligence (AIOps) ([View Highlight](https://read.readwise.io/read/01fsm2gnvfv0vfd782v6c35aq4))
> It is about an *extension* of observability, granting the tooling the power to *act* in an automated fashion on the insights provided by the analysis of telemetry. How well that works in practice depends on how well the observability tooling understands the failure modes, and how reliable are the runbooks that are executed to remediate the issues. ([View Highlight](https://read.readwise.io/read/01fsm2h8n8a4z4qxwr98fg0bdw))
> observability tooling does *root cause fencing*: it tells you which errors are occurring, where in your systems they happen, and an approximation of how failures spreads across a system (distributed tracing is not yet a science, especially when it comes to defining the causality between parent and child spans). The interpretation of what leads to what else – or, in other words, the *causality between observed phenomena* – in most cases still requires a human well-versed in the specifics of the technologies involved. ([View Highlight](https://read.readwise.io/read/01fsm2hy5d4q2g529m1ppymx0t))
> But will an AI manage to analyze unknown problems from the available telemetry and fix it reliably? I frankly don’t see it happening. ([View Highlight](https://read.readwise.io/read/01fsm2j6dw88sxcrkzkt21n1zt))
> There seems to be an increasing consensus that observability is *more* than the monitoring “of yore”. The difference between the two, however, is not clearly understood and the discussion is clearly driven by commercial entities that have vested interests in setting particular offerings aside. There is also, very interestingly, a strong geographical component to the search patterns for observability and monitoring. Nevertheless, at the end of the day, monitoring and observability are terms still mostly interchangeable in the parlance, and it is going to be fascinating to see how the situation evolves in the coming years. ([View Highlight](https://read.readwise.io/read/01fsm2jdk3q35y91hdncy3sdtj))
---
Title: Observability vs. Monitoring Debate: An Irreverent View
Author: Michele Mancioppi
Tags: readwise, articles
date: 2024-01-30
---
# Observability vs. Monitoring Debate: An Irreverent View

URL:: https://ubuntu.com/blog/observability-vs-monitoring-debate-an-irreverent-view
Author:: Michele Mancioppi
## AI-Generated Summary
This post provides an irreverent view on the debate around observability vs. monitoring, which is a rather confounding topic. […]
## Highlights
> Trope 1: Pillars ([View Highlight](https://read.readwise.io/read/01fsm2f6gh3gznnb86kjfxaa48))
> The word “pillar” is often used in the observability/monitoring context to represent which types of telemetry are collected and processed by a tool, e.g., metrics, logs, distributed tracing, synthetic monitoring, production profiling, and so on. Some telemetry types are very well understood and widely adopted, such as logs and metrics; others less so, such as distributed tracing, synthetic monitoring and continuous profiling. (Profiling in and of itself is well understood from a development and QA standpoint, but not how to use profilers continuously in production.) ([View Highlight](https://read.readwise.io/read/01fsm2eg15kdh2nd3fhgetfnx8))
> In reality, there are many types of telemetry, and which ones are needed depends on the particular use case. What there surely isn’t, is a “golden set” of telemetry types that give you just what you need no matter what. The kind of telemetry you need is very dependent on what your application does, who uses it, and how. ([View Highlight](https://read.readwise.io/read/01fsm2f2gjjywqz8mbgr59nsew))
> Trope 2: Observability is monitoring plus powerful analytics ([View Highlight](https://read.readwise.io/read/01fsm2f8pat5yymvvfxd96mzx5))
> It is true that, in the past few years, the flexibility of analyzing telemetry has improved by leaps and bounds. How those *incremental improvements* make a sharp cut between monitoring and observability is honestly beyond me. ([View Highlight](https://read.readwise.io/read/01fsm2gkhg6hmww90zr6x8c97w))
> Trope 3: Artificial intelligence (AIOps) ([View Highlight](https://read.readwise.io/read/01fsm2gnvfv0vfd782v6c35aq4))
> It is about an *extension* of observability, granting the tooling the power to *act* in an automated fashion on the insights provided by the analysis of telemetry. How well that works in practice depends on how well the observability tooling understands the failure modes, and how reliable are the runbooks that are executed to remediate the issues. ([View Highlight](https://read.readwise.io/read/01fsm2h8n8a4z4qxwr98fg0bdw))
> observability tooling does *root cause fencing*: it tells you which errors are occurring, where in your systems they happen, and an approximation of how failures spreads across a system (distributed tracing is not yet a science, especially when it comes to defining the causality between parent and child spans). The interpretation of what leads to what else – or, in other words, the *causality between observed phenomena* – in most cases still requires a human well-versed in the specifics of the technologies involved. ([View Highlight](https://read.readwise.io/read/01fsm2hy5d4q2g529m1ppymx0t))
> But will an AI manage to analyze unknown problems from the available telemetry and fix it reliably? I frankly don’t see it happening. ([View Highlight](https://read.readwise.io/read/01fsm2j6dw88sxcrkzkt21n1zt))
> There seems to be an increasing consensus that observability is *more* than the monitoring “of yore”. The difference between the two, however, is not clearly understood and the discussion is clearly driven by commercial entities that have vested interests in setting particular offerings aside. There is also, very interestingly, a strong geographical component to the search patterns for observability and monitoring. Nevertheless, at the end of the day, monitoring and observability are terms still mostly interchangeable in the parlance, and it is going to be fascinating to see how the situation evolves in the coming years. ([View Highlight](https://read.readwise.io/read/01fsm2jdk3q35y91hdncy3sdtj))