# Roblox Return to Service 10/28-10/31 2021

URL:: https://blog.roblox.com/2022/01/roblox-return-to-service-10-28-10-31-2021
Author:: Roblox Blog
## Highlights
> Starting October 28th and fully resolving on October 31st, Roblox experienced a 73-hour outage.¹ Fifty million players regularly use Roblox every day and, to create the experience our players expect, our scale involves hundreds of internal online services. As with any large-scale service, we have service interruptions from time to time, but the extended length of this outage makes it particularly noteworthy. We sincerely apologize to our community for the downtime. ([View Highlight](https://read.readwise.io/read/01fsy080y8qwz83s67fkqr9zf8))
> • The root cause was due to two issues. Enabling a relatively new streaming feature on Consul under unusually high read and write load led to excessive contention and poor performance. In addition, our particular load conditions triggered a pathological performance issue in BoltDB. The open source BoltDB system is used within Consul to manage write-ahead-logs for leader election and data replication. ([View Highlight](https://read.readwise.io/read/01fsy089t5jefe2rky82y0exqd))
> • A single Consul cluster supporting multiple workloads exacerbated the impact of these issues. ([View Highlight](https://read.readwise.io/read/01fsy09fc3f9yaprd4r929s5et))
> • Challenges in diagnosing these two primarily unrelated issues buried deep in the Consul implementation were largely responsible for the extended downtime. ([View Highlight](https://read.readwise.io/read/01fsy09zvky6n82yh4exj3cj83))
> • Critical monitoring systems that would have provided better visibility into the cause of the outage relied on affected systems, such as Consul. This combination severely hampered the triage process. ([View Highlight](https://read.readwise.io/read/01fsy0a9mkmhg6nnp0enak9wk2))
> • We have accelerated engineering efforts to improve our monitoring, remove circular dependencies in our observability stack, as well as accelerating our bootstrapping process. ([View Highlight](https://read.readwise.io/read/01fsy0ag587hk29y8493h803wy))
> • We are working to move to multiple availability zones and data centers. ([View Highlight](https://read.readwise.io/read/01fsy0ahc7ep1p5q7vy671qccq))
> Roblox’s core infrastructure runs in Roblox data centers. We deploy and manage our own hardware, as well as our own compute, storage, and networking systems on top of that hardware. The scale of our deployment is significant, with over 18,000 servers and 170,000 containers. ([View Highlight](https://read.readwise.io/read/01fsy0arrfsqbk99habd53pvba))
> In order to run thousands of servers across multiple sites, we leverage a technology suite commonly known as the “[HashiStack](https://www.hashicorp.com/resources/how-we-used-the-hashistack-to-transform-the-world-of-roblox).” **Nomad**, **Consul** and **Vault** are the technologies that we use to manage servers and services around the world, and that allow us to orchestrate containers that support Roblox services. ([View Highlight](https://read.readwise.io/read/01fsy0aye4kx6ec6f2jncmmdry))
> Nomad is used for scheduling work. It decides which containers are going to run on which nodes and on which ports they’re accessible. It also validates container health. All of this data is relayed to a Service Registry, which is a database of IP:Port combinations. Roblox services use the Service Registry to find one another so they can communicate. This process is called “service discovery.” We use **Consul** for service discovery, health checks, session locking (for HA systems built on-top), and as a KV store. ([View Highlight](https://read.readwise.io/read/01fsy0bmcfkc4sce7z5kmteysv))
> Consul is deployed as a cluster of machines in two roles. “Voters” (5 machines) authoritatively hold the state of the cluster; “Non-voters” (5 additional machines) are read-only replicas that assist with scaling read requests. At any given time, one of the voters is elected by the cluster as leader. The leader is responsible for replicating data to the other voters and determining if written data has been fully committed. Consul uses an algorithm called [Raft](https://raft.github.io/) for leader election and to distribute state across the cluster in a way that ensures each node in the cluster agrees upon the updates. It is not uncommon for the leader to change via leader election several times throughout a given day. ([View Highlight](https://read.readwise.io/read/01fsy0c0ncxht791phykz5x56z))
> 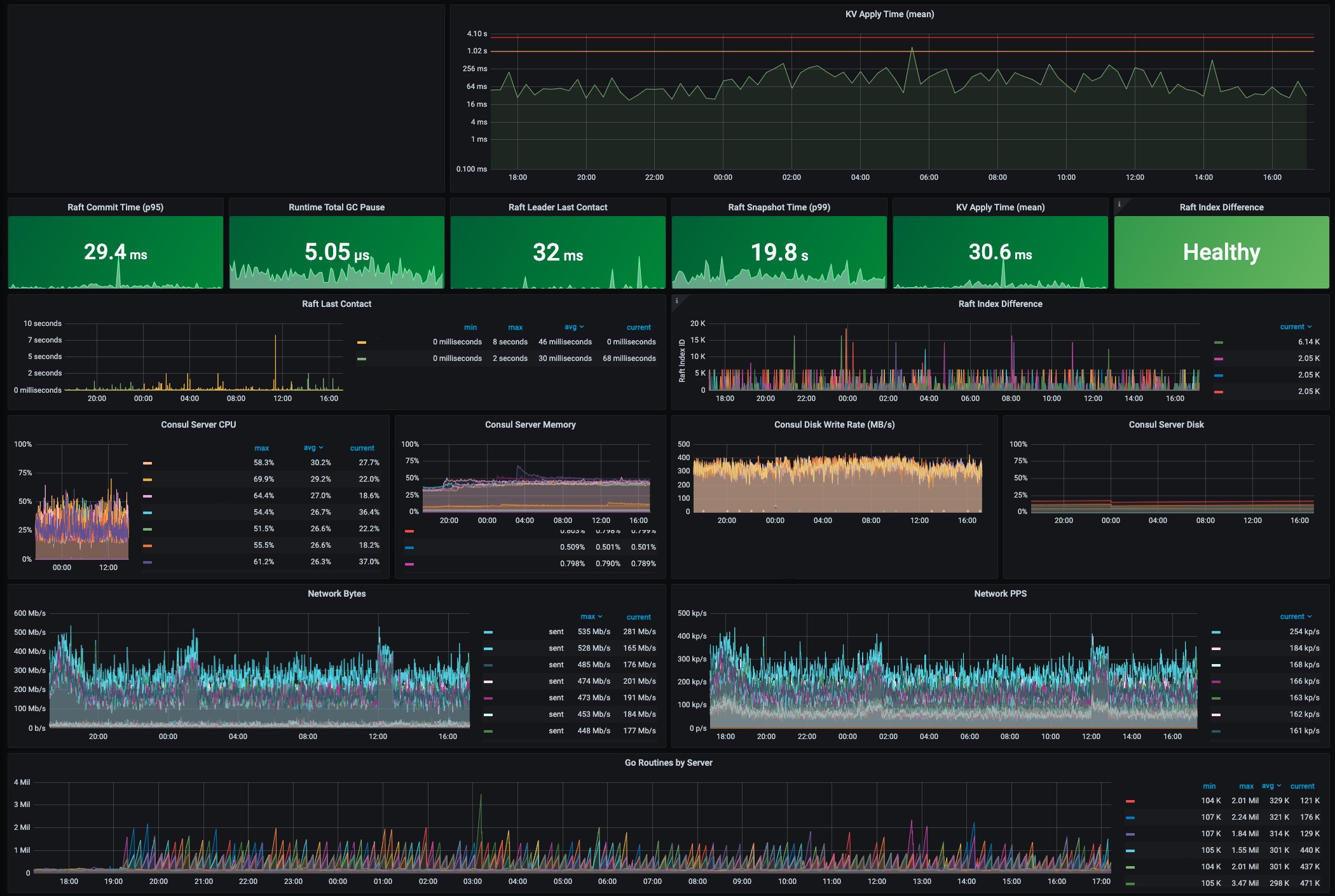
> 1. Normal Operations of the Consul at Roblox ([View Highlight](https://read.readwise.io/read/01fsy0c2zp7xydtc62r8tdkag3))
> Hardware issues are not unusual at Roblox’s scale, and Consul can survive hardware failure. However, if hardware is merely slow rather than failing, it can impact overall Consul performance. ([View Highlight](https://read.readwise.io/read/01fsy0d1nwc52872qgfrc9twvd))
> 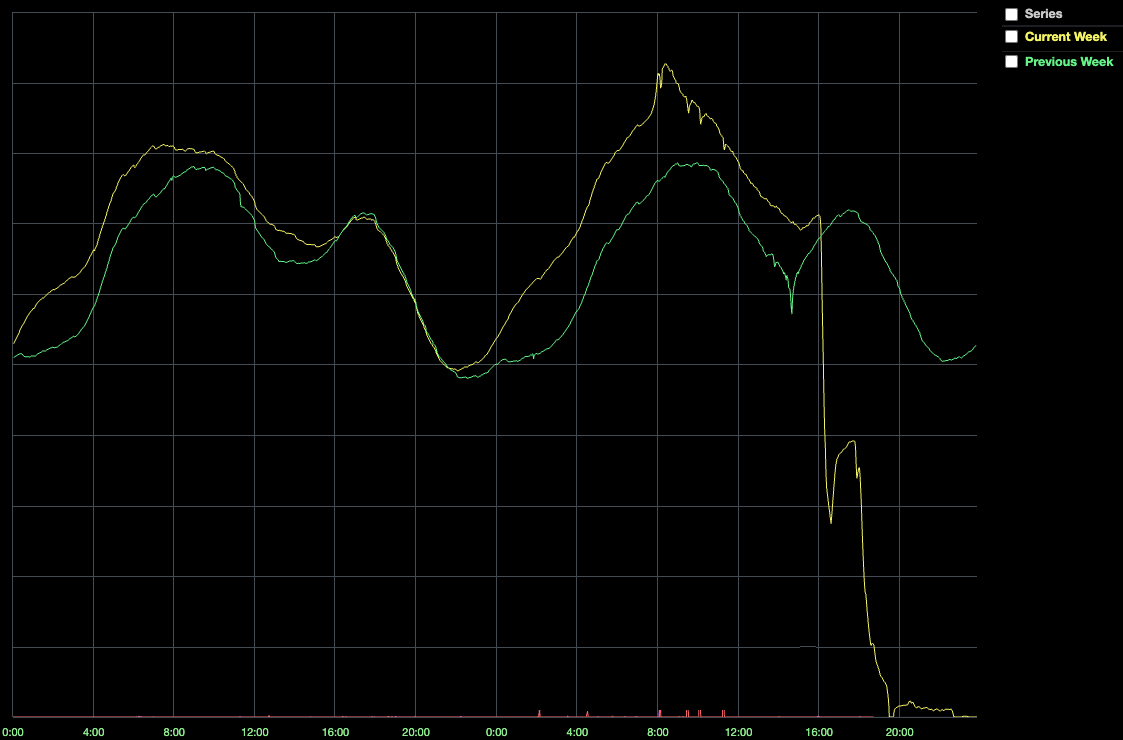 ([View Highlight](https://read.readwise.io/read/01fsy0dcmknhcgw6n2pdzzdphq))
> This drop coincided with a significant degradation in system health, which ultimately resulted in a complete system outage. Why? When a Roblox service wants to talk to another service, it relies on Consul to have up-to-date knowledge of the location of the service it wants to talk to. However, if Consul is unhealthy, servers struggle to connect. Furthermore, Nomad and Vault rely on Consul, so when Consul is unhealthy, the system cannot schedule new containers or retrieve production secrets used for authentication. In short, the system failed because Consul was a single point of failure, and Consul was not healthy. ([View Highlight](https://read.readwise.io/read/01fsy0dqptgadftf9zmxsjmfw4))
> We had ruled out hardware failure. Faster hardware hadn’t helped and, as we learned later, potentially hurt stability. Resetting Consul’s internal state hadn’t helped either. There was no user traffic coming in, yet Consul was still slow. We had leveraged iptables to let traffic back into the cluster slowly. Was the cluster simply getting pushed back into an unhealthy state by the sheer volume of thousands of containers trying to reconnect? This was our third attempt at diagnosing the root cause of the incident**.** ([View Highlight](https://read.readwise.io/read/01fsy0f58kyjtp6jqb578kgyyy))
> This data showed Consul KV writes getting blocked for long periods of time. In other words, “contention.” ([View Highlight](https://read.readwise.io/read/01fsy0gdnb7bgs3nhn84tr2tpj))
> Several months ago, we enabled a new Consul streaming feature on a subset of our services. This feature, designed to lower the CPU usage and network bandwidth of the Consul cluster, worked as expected, so over the next few months we incrementally enabled the feature on more of our backend services. On October 27th at 14:00, one day before the outage, we enabled this feature on a backend service that is responsible for traffic routing. As part of this rollout, in order to prepare for the increased traffic we typically see at the end of the year, we also increased the number of nodes supporting traffic routing by 50%. The system had worked well with streaming at this level for a day before the incident started, so it wasn’t initially clear why it’s performance had changed. However through analysis of perf reports and flame graphs from Consul servers, we saw evidence of streaming code paths being responsible for the contention causing high CPU usage. We disabled the streaming feature for all Consul systems, including the traffic routing nodes. The config change finished propagating at 15:51, at which time the 50th percentile for Consul KV writes lowered to 300ms. We finally had a breakthrough. ([View Highlight](https://read.readwise.io/read/01fsy0hg4t6ah3jp7642vw9804))
> Why was streaming an issue? HashiCorp explained that, while streaming was overall more efficient, it used fewer concurrency control elements (Go channels) in its implementation than long polling. Under very high load – specifically, both a very high read load and a very high write load – the design of streaming exacerbates the amount of contention on a single Go channel, which causes blocking during writes, making it significantly less efficient. This behavior also explained the effect of higher core-count servers: those servers were dual socket architectures with a NUMA memory model. The additional contention on shared resources thus got worse under this architecture. By turning off streaming, we dramatically improved the health of the Consul cluster. ([View Highlight](https://read.readwise.io/read/01fsy0kytz8z4hwbkx9maebgck))
> Consul uses a popular open-source persistence library named BoltDB to store Raft logs. It is *not* used to store the current state within Consul, but rather a rolling log of the operations being applied. To prevent BoltDB from growing indefinitely, Consul regularly performs snapshots. The snapshot operation writes the current state of Consul to disk and then deletes the oldest log entries from BoltDB.
> However, due to the design of BoltDB, even when the oldest log entries are deleted, the space BoltDB uses on disk never shrinks. Instead, all the pages (4kb segments within the file) that were used to store deleted data are instead marked as “free” and re-used for subsequent writes. BoltDB tracks these free pages in a structure called its “freelist.” Typically, write latency is not meaningfully impacted by the time it takes to update the freelist, but Roblox’s workload exposed a pathological performance issue in BoltDB that made freelist maintenance extremely expensive. ([View Highlight](https://read.readwise.io/read/01fsy0nnvw3c286mc8mc9j4b98))
> Roblox uses a typical microservices pattern for its backend. At the bottom of the microservices “stack” are databases and caches. These databases were unaffected by the outage, but the caching system, which regularly handles 1B requests-per-second across its multiple layers during regular system operation, was unhealthy. Since our caches store transient data that can easily repopulate from the underlying databases, the easiest way to bring the caching system back into a healthy state was to redeploy it. ([View Highlight](https://read.readwise.io/read/01fsy0p7axtm1pee7mydxva2fv))
> • The caching system’s automated deployment tool was built to support incremental adjustments to large scale deployments that were already handling traffic at scale, not iterative attempts to bootstrap a large cluster from scratch. ([View Highlight](https://read.readwise.io/read/01fsy0pm272rp9vpnqjm63b41e))
> With cold caches and a system we were still uncertain about, we did not want a flood of traffic that could potentially put the system back into an unstable state. To avoid a flood, we used DNS steering to manage the number of players who could access Roblox. This allowed us to let in a certain percentage of randomly selected players while others continued to be redirected to our static maintenance page. Every time we increased the percentage, we checked database load, cache performance, and overall system stability. Work continued throughout the day, ratcheting up access in roughly 10% increments. We enjoyed seeing some of our most dedicated players figure out our DNS steering scheme and start exchanging this information on Twitter so that they could get “early” access as we brought the service back up. At 16:45 Sunday, 73 hours after the start of the outage, 100% of players were given access and Roblox was fully operational. ([View Highlight](https://read.readwise.io/read/01fsy0qkfbt8samw0qw8fa1jqa))
> While HashiCorp had [benchmarked streaming](https://www.hashicorp.com/cgsb) at similar scale to Roblox usage, they had not observed this specific behavior before due to it manifesting from a combination of both a large number of streams and a high churn rate. ([View Highlight](https://read.readwise.io/read/01fsy0rjw3za7pb7hw94zdmx73))
> The full list of completed and in-flight reliability improvements is too long and too detailed for this write-up, but here are the key items: ([View Highlight](https://read.readwise.io/read/01fsy0st16gtq539bnz889nhdy))
> **Telemetry Improvements** ([View Highlight](https://read.readwise.io/read/01fsy0szmmhzjg75tbjedp8zqh))
> There was a circular dependency between our telemetry systems and Consul, which meant that when Consul was unhealthy, we lacked the telemetry data that would have made it easier for us to figure out what was wrong. We have removed this circular dependency. Our telemetry systems no longer depend on the systems that they are configured to monitor. ([View Highlight](https://read.readwise.io/read/01fsy0t2jeq7ar7nkp02cs1ax0))
> **Expansion Into Multiple Availability Zones and Data Centers** ([View Highlight](https://read.readwise.io/read/01fsy0t99ezngvawnc7grcnq8y))
> Running all Roblox backend services on one Consul cluster left us exposed to an outage of this nature. We have already built out the servers and networking for an additional, geographically distinct data center that will host our backend services. We have efforts underway to move to multiple availability zones within these data centers; we have made major modifications to our engineering roadmap and our staffing plans in order to accelerate these efforts. ([View Highlight](https://read.readwise.io/read/01fsy0tcb6xnq2dn2emfgepzq2))
> **Consul Upgrades and Sharding** ([View Highlight](https://read.readwise.io/read/01fsy0tdsq0fhdghgzk5f9c4vm))
> Roblox is still growing quickly, so even with multiple Consul clusters, we want to reduce the load we place on Consul. We have reviewed how our services use Consul’s KV store and health checks, and have split some critical services into their own dedicated clusters, reducing load on our central Consul cluster to a safer level. ([View Highlight](https://read.readwise.io/read/01fsy0twdyz7p3gqbxm8k262vy))
> We discovered a large amount of obsolete KV data. Deleting this obsolete data improved Consul performance. ([View Highlight](https://read.readwise.io/read/01fsy0v1f2ffb72bkwzyhdmj79))
> **Improvements To Bootstrapping Procedures and Config Management** ([View Highlight](https://read.readwise.io/read/01fsy0v3bt3c7ed56193k5n484))
> we have redesigned our cache deployment mechanisms to ensure we can quickly bring up our cache system from a standing start. Implementation of this is underway. ([View Highlight](https://read.readwise.io/read/01fsy0vrhgq2nad5q11e4jsb8f))
> **Reintroduction of Streaming** ([View Highlight](https://read.readwise.io/read/01fsy0w1bnb0qqfja81gr1jvrc))
> We originally deployed streaming to lower the CPU usage and network bandwidth of the Consul cluster. Once a new implementation has been tested at our scale with our workload, we expect to carefully reintroduce it to our systems. ([View Highlight](https://read.readwise.io/read/01fsy0w23jqqrgamm04tfzz42n))
> In the aftermath of an outage like this, it’s natural to ask if Roblox would consider moving to public cloud and letting a third party manage our foundational compute, storage, and networking services. ([View Highlight](https://read.readwise.io/read/01fsy0w8aecsey5zs13385a4m9))
> Another one of our Roblox values is Take The Long View, and this value heavily informs our decision-making. We build and manage our own foundational infrastructure on-prem because, at our current scale, and more importantly, the scale that we know we’ll reach as our platform grows, we believe it’s the best way to support our business and our community. Specifically, by building and managing our own data centers for backend and network edge services, we have been able to significantly control costs compared to public cloud. These savings directly influence the amount we are able to pay to creators on the platform. Furthermore, owning our own hardware and building our own edge infrastructure allows us to minimize performance variations and carefully manage the latency of our players around the world. Consistent performance and low latency are critical to the experience of our players, who are not necessarily located near the data centers of public cloud providers. ([View Highlight](https://read.readwise.io/read/01fsy0wrr8ay6tq785xpcfrmmf))
> Roblox typically receives a surge of traffic at the end of December. We have a lot more reliability work to do, but we are pleased to report that Roblox did not have a single significant production incident during the December surge, and that the performance and stability of both Consul and Nomad during this surge were excellent. It appears that our immediate reliability improvements are already paying off, and as our longer term projects wrap up we expect even better results. ([View Highlight](https://read.readwise.io/read/01fsy0xjav31xrd0q5kbv5eg21))
> At Roblox we believe in civility and respect. It’s easy to be civil and respectful when things are going well, but the real test is how we treat one another when things get difficult. ([View Highlight](https://read.readwise.io/read/01fsy0y1smqs29m6zbmkvn7zew))
---
Title: Roblox Return to Service 10/28-10/31 2021
Author: Roblox Blog
Tags: readwise, articles
date: 2024-01-30
---
# Roblox Return to Service 10/28-10/31 2021

URL:: https://blog.roblox.com/2022/01/roblox-return-to-service-10-28-10-31-2021
Author:: Roblox Blog
## AI-Generated Summary
Starting October 28th and fully resolving on October 31st, Roblox experienced a 73-hour outage. We’re sharing these technical details to give our community an understanding of the root cause of the problem, how we addressed it, and what we are doing to prevent similar issues from happening in the future.
## Highlights
> Starting October 28th and fully resolving on October 31st, Roblox experienced a 73-hour outage.¹ Fifty million players regularly use Roblox every day and, to create the experience our players expect, our scale involves hundreds of internal online services. As with any large-scale service, we have service interruptions from time to time, but the extended length of this outage makes it particularly noteworthy. We sincerely apologize to our community for the downtime. ([View Highlight](https://read.readwise.io/read/01fsy080y8qwz83s67fkqr9zf8))
> • The root cause was due to two issues. Enabling a relatively new streaming feature on Consul under unusually high read and write load led to excessive contention and poor performance. In addition, our particular load conditions triggered a pathological performance issue in BoltDB. The open source BoltDB system is used within Consul to manage write-ahead-logs for leader election and data replication. ([View Highlight](https://read.readwise.io/read/01fsy089t5jefe2rky82y0exqd))
> • A single Consul cluster supporting multiple workloads exacerbated the impact of these issues. ([View Highlight](https://read.readwise.io/read/01fsy09fc3f9yaprd4r929s5et))
> • Challenges in diagnosing these two primarily unrelated issues buried deep in the Consul implementation were largely responsible for the extended downtime. ([View Highlight](https://read.readwise.io/read/01fsy09zvky6n82yh4exj3cj83))
> • Critical monitoring systems that would have provided better visibility into the cause of the outage relied on affected systems, such as Consul. This combination severely hampered the triage process. ([View Highlight](https://read.readwise.io/read/01fsy0a9mkmhg6nnp0enak9wk2))
> • We have accelerated engineering efforts to improve our monitoring, remove circular dependencies in our observability stack, as well as accelerating our bootstrapping process. ([View Highlight](https://read.readwise.io/read/01fsy0ag587hk29y8493h803wy))
> • We are working to move to multiple availability zones and data centers. ([View Highlight](https://read.readwise.io/read/01fsy0ahc7ep1p5q7vy671qccq))
> Roblox’s core infrastructure runs in Roblox data centers. We deploy and manage our own hardware, as well as our own compute, storage, and networking systems on top of that hardware. The scale of our deployment is significant, with over 18,000 servers and 170,000 containers. ([View Highlight](https://read.readwise.io/read/01fsy0arrfsqbk99habd53pvba))
> In order to run thousands of servers across multiple sites, we leverage a technology suite commonly known as the “[HashiStack](https://www.hashicorp.com/resources/how-we-used-the-hashistack-to-transform-the-world-of-roblox).” **Nomad**, **Consul** and **Vault** are the technologies that we use to manage servers and services around the world, and that allow us to orchestrate containers that support Roblox services. ([View Highlight](https://read.readwise.io/read/01fsy0aye4kx6ec6f2jncmmdry))
> Nomad is used for scheduling work. It decides which containers are going to run on which nodes and on which ports they’re accessible. It also validates container health. All of this data is relayed to a Service Registry, which is a database of IP:Port combinations. Roblox services use the Service Registry to find one another so they can communicate. This process is called “service discovery.” We use **Consul** for service discovery, health checks, session locking (for HA systems built on-top), and as a KV store. ([View Highlight](https://read.readwise.io/read/01fsy0bmcfkc4sce7z5kmteysv))
> Consul is deployed as a cluster of machines in two roles. “Voters” (5 machines) authoritatively hold the state of the cluster; “Non-voters” (5 additional machines) are read-only replicas that assist with scaling read requests. At any given time, one of the voters is elected by the cluster as leader. The leader is responsible for replicating data to the other voters and determining if written data has been fully committed. Consul uses an algorithm called [Raft](https://raft.github.io/) for leader election and to distribute state across the cluster in a way that ensures each node in the cluster agrees upon the updates. It is not uncommon for the leader to change via leader election several times throughout a given day. ([View Highlight](https://read.readwise.io/read/01fsy0c0ncxht791phykz5x56z))
> 
> 1. Normal Operations of the Consul at Roblox ([View Highlight](https://read.readwise.io/read/01fsy0c2zp7xydtc62r8tdkag3))
> Hardware issues are not unusual at Roblox’s scale, and Consul can survive hardware failure. However, if hardware is merely slow rather than failing, it can impact overall Consul performance. ([View Highlight](https://read.readwise.io/read/01fsy0d1nwc52872qgfrc9twvd))
>  ([View Highlight](https://read.readwise.io/read/01fsy0dcmknhcgw6n2pdzzdphq))
> This drop coincided with a significant degradation in system health, which ultimately resulted in a complete system outage. Why? When a Roblox service wants to talk to another service, it relies on Consul to have up-to-date knowledge of the location of the service it wants to talk to. However, if Consul is unhealthy, servers struggle to connect. Furthermore, Nomad and Vault rely on Consul, so when Consul is unhealthy, the system cannot schedule new containers or retrieve production secrets used for authentication. In short, the system failed because Consul was a single point of failure, and Consul was not healthy. ([View Highlight](https://read.readwise.io/read/01fsy0dqptgadftf9zmxsjmfw4))
> We had ruled out hardware failure. Faster hardware hadn’t helped and, as we learned later, potentially hurt stability. Resetting Consul’s internal state hadn’t helped either. There was no user traffic coming in, yet Consul was still slow. We had leveraged iptables to let traffic back into the cluster slowly. Was the cluster simply getting pushed back into an unhealthy state by the sheer volume of thousands of containers trying to reconnect? This was our third attempt at diagnosing the root cause of the incident**.** ([View Highlight](https://read.readwise.io/read/01fsy0f58kyjtp6jqb578kgyyy))
> This data showed Consul KV writes getting blocked for long periods of time. In other words, “contention.” ([View Highlight](https://read.readwise.io/read/01fsy0gdnb7bgs3nhn84tr2tpj))
> Several months ago, we enabled a new Consul streaming feature on a subset of our services. This feature, designed to lower the CPU usage and network bandwidth of the Consul cluster, worked as expected, so over the next few months we incrementally enabled the feature on more of our backend services. On October 27th at 14:00, one day before the outage, we enabled this feature on a backend service that is responsible for traffic routing. As part of this rollout, in order to prepare for the increased traffic we typically see at the end of the year, we also increased the number of nodes supporting traffic routing by 50%. The system had worked well with streaming at this level for a day before the incident started, so it wasn’t initially clear why it’s performance had changed. However through analysis of perf reports and flame graphs from Consul servers, we saw evidence of streaming code paths being responsible for the contention causing high CPU usage. We disabled the streaming feature for all Consul systems, including the traffic routing nodes. The config change finished propagating at 15:51, at which time the 50th percentile for Consul KV writes lowered to 300ms. We finally had a breakthrough. ([View Highlight](https://read.readwise.io/read/01fsy0hg4t6ah3jp7642vw9804))
> Why was streaming an issue? HashiCorp explained that, while streaming was overall more efficient, it used fewer concurrency control elements (Go channels) in its implementation than long polling. Under very high load – specifically, both a very high read load and a very high write load – the design of streaming exacerbates the amount of contention on a single Go channel, which causes blocking during writes, making it significantly less efficient. This behavior also explained the effect of higher core-count servers: those servers were dual socket architectures with a NUMA memory model. The additional contention on shared resources thus got worse under this architecture. By turning off streaming, we dramatically improved the health of the Consul cluster. ([View Highlight](https://read.readwise.io/read/01fsy0kytz8z4hwbkx9maebgck))
> Consul uses a popular open-source persistence library named BoltDB to store Raft logs. It is *not* used to store the current state within Consul, but rather a rolling log of the operations being applied. To prevent BoltDB from growing indefinitely, Consul regularly performs snapshots. The snapshot operation writes the current state of Consul to disk and then deletes the oldest log entries from BoltDB.
> However, due to the design of BoltDB, even when the oldest log entries are deleted, the space BoltDB uses on disk never shrinks. Instead, all the pages (4kb segments within the file) that were used to store deleted data are instead marked as “free” and re-used for subsequent writes. BoltDB tracks these free pages in a structure called its “freelist.” Typically, write latency is not meaningfully impacted by the time it takes to update the freelist, but Roblox’s workload exposed a pathological performance issue in BoltDB that made freelist maintenance extremely expensive. ([View Highlight](https://read.readwise.io/read/01fsy0nnvw3c286mc8mc9j4b98))
> Roblox uses a typical microservices pattern for its backend. At the bottom of the microservices “stack” are databases and caches. These databases were unaffected by the outage, but the caching system, which regularly handles 1B requests-per-second across its multiple layers during regular system operation, was unhealthy. Since our caches store transient data that can easily repopulate from the underlying databases, the easiest way to bring the caching system back into a healthy state was to redeploy it. ([View Highlight](https://read.readwise.io/read/01fsy0p7axtm1pee7mydxva2fv))
> • The caching system’s automated deployment tool was built to support incremental adjustments to large scale deployments that were already handling traffic at scale, not iterative attempts to bootstrap a large cluster from scratch. ([View Highlight](https://read.readwise.io/read/01fsy0pm272rp9vpnqjm63b41e))
> With cold caches and a system we were still uncertain about, we did not want a flood of traffic that could potentially put the system back into an unstable state. To avoid a flood, we used DNS steering to manage the number of players who could access Roblox. This allowed us to let in a certain percentage of randomly selected players while others continued to be redirected to our static maintenance page. Every time we increased the percentage, we checked database load, cache performance, and overall system stability. Work continued throughout the day, ratcheting up access in roughly 10% increments. We enjoyed seeing some of our most dedicated players figure out our DNS steering scheme and start exchanging this information on Twitter so that they could get “early” access as we brought the service back up. At 16:45 Sunday, 73 hours after the start of the outage, 100% of players were given access and Roblox was fully operational. ([View Highlight](https://read.readwise.io/read/01fsy0qkfbt8samw0qw8fa1jqa))
> While HashiCorp had [benchmarked streaming](https://www.hashicorp.com/cgsb) at similar scale to Roblox usage, they had not observed this specific behavior before due to it manifesting from a combination of both a large number of streams and a high churn rate. ([View Highlight](https://read.readwise.io/read/01fsy0rjw3za7pb7hw94zdmx73))
> The full list of completed and in-flight reliability improvements is too long and too detailed for this write-up, but here are the key items: ([View Highlight](https://read.readwise.io/read/01fsy0st16gtq539bnz889nhdy))
> **Telemetry Improvements** ([View Highlight](https://read.readwise.io/read/01fsy0szmmhzjg75tbjedp8zqh))
> There was a circular dependency between our telemetry systems and Consul, which meant that when Consul was unhealthy, we lacked the telemetry data that would have made it easier for us to figure out what was wrong. We have removed this circular dependency. Our telemetry systems no longer depend on the systems that they are configured to monitor. ([View Highlight](https://read.readwise.io/read/01fsy0t2jeq7ar7nkp02cs1ax0))
> **Expansion Into Multiple Availability Zones and Data Centers** ([View Highlight](https://read.readwise.io/read/01fsy0t99ezngvawnc7grcnq8y))
> Running all Roblox backend services on one Consul cluster left us exposed to an outage of this nature. We have already built out the servers and networking for an additional, geographically distinct data center that will host our backend services. We have efforts underway to move to multiple availability zones within these data centers; we have made major modifications to our engineering roadmap and our staffing plans in order to accelerate these efforts. ([View Highlight](https://read.readwise.io/read/01fsy0tcb6xnq2dn2emfgepzq2))
> **Consul Upgrades and Sharding** ([View Highlight](https://read.readwise.io/read/01fsy0tdsq0fhdghgzk5f9c4vm))
> Roblox is still growing quickly, so even with multiple Consul clusters, we want to reduce the load we place on Consul. We have reviewed how our services use Consul’s KV store and health checks, and have split some critical services into their own dedicated clusters, reducing load on our central Consul cluster to a safer level. ([View Highlight](https://read.readwise.io/read/01fsy0twdyz7p3gqbxm8k262vy))
> We discovered a large amount of obsolete KV data. Deleting this obsolete data improved Consul performance. ([View Highlight](https://read.readwise.io/read/01fsy0v1f2ffb72bkwzyhdmj79))
> **Improvements To Bootstrapping Procedures and Config Management** ([View Highlight](https://read.readwise.io/read/01fsy0v3bt3c7ed56193k5n484))
> we have redesigned our cache deployment mechanisms to ensure we can quickly bring up our cache system from a standing start. Implementation of this is underway. ([View Highlight](https://read.readwise.io/read/01fsy0vrhgq2nad5q11e4jsb8f))
> **Reintroduction of Streaming** ([View Highlight](https://read.readwise.io/read/01fsy0w1bnb0qqfja81gr1jvrc))
> We originally deployed streaming to lower the CPU usage and network bandwidth of the Consul cluster. Once a new implementation has been tested at our scale with our workload, we expect to carefully reintroduce it to our systems. ([View Highlight](https://read.readwise.io/read/01fsy0w23jqqrgamm04tfzz42n))
> In the aftermath of an outage like this, it’s natural to ask if Roblox would consider moving to public cloud and letting a third party manage our foundational compute, storage, and networking services. ([View Highlight](https://read.readwise.io/read/01fsy0w8aecsey5zs13385a4m9))
> Another one of our Roblox values is Take The Long View, and this value heavily informs our decision-making. We build and manage our own foundational infrastructure on-prem because, at our current scale, and more importantly, the scale that we know we’ll reach as our platform grows, we believe it’s the best way to support our business and our community. Specifically, by building and managing our own data centers for backend and network edge services, we have been able to significantly control costs compared to public cloud. These savings directly influence the amount we are able to pay to creators on the platform. Furthermore, owning our own hardware and building our own edge infrastructure allows us to minimize performance variations and carefully manage the latency of our players around the world. Consistent performance and low latency are critical to the experience of our players, who are not necessarily located near the data centers of public cloud providers. ([View Highlight](https://read.readwise.io/read/01fsy0wrr8ay6tq785xpcfrmmf))
> Roblox typically receives a surge of traffic at the end of December. We have a lot more reliability work to do, but we are pleased to report that Roblox did not have a single significant production incident during the December surge, and that the performance and stability of both Consul and Nomad during this surge were excellent. It appears that our immediate reliability improvements are already paying off, and as our longer term projects wrap up we expect even better results. ([View Highlight](https://read.readwise.io/read/01fsy0xjav31xrd0q5kbv5eg21))
> At Roblox we believe in civility and respect. It’s easy to be civil and respectful when things are going well, but the real test is how we treat one another when things get difficult. ([View Highlight](https://read.readwise.io/read/01fsy0y1smqs29m6zbmkvn7zew))